Contoso has an Azure subscription in North Europe that contains the corporate infrastructure. The current infrastructure contains a Microsoft SQL Server 2017 database. The database contains the following tables.
The FeedbackJson column has a full-text index and stores JSON documents in the following format.
The support staff at Contoso never has the unmask permission.
Requirements
Contoso is deploying a new Azure SQL database that will become the authoritative data store for the following;
• Alworkloads
• Vector search
• Modernized API access
• Retrieval Augmented Generation (RAG) pipelines
Sometimesthe ingestion pipeline fails due to malformed JSON and duplicate payloads.
The engineers at Contoso report that the following dashboard query runs slowly.
SELECT VehicleTd, Lastupdatedutc, EngineStatus, BatteryHealth FROM dbo.VehicleHealthSumary where fleetld- gFleetld ORDER BV LastUpdatedUtc DESC;
You review the execution plan and discover that the plan shows a clustered index scan.
vehicleincidentReports often contains details about the weather, traffic conditions, and location. Analysts report that it is difficult to find similar incidents based on these details
Planned Changes
Contoso wants to modernize Fleet Intelligence Platform to support Al-powered semantic search over
incident reports.
Security Requirements
Contoso identifies the following telemetry requirements:
• Telemetry data must be stored in a partitioned table.
• Telemetry data must provide predictable performance for ingestion and retention operations.
• latitude, longitude, and accuracy JSON properties must be filtered by using an index seek.
Contoso identifies the following maintenance data requirements:
• Ensure that any changes to a row in the MaintenanceEvents table updates the corresponding
value in the LastModif reduce column to the time of the change.
• Avoidrecursive updates.
AI Search, Embedding’s, and Vector indexing
The development learn at Contoso will use Microsoft Visual Studio Code and GitHub Copilot and will
retrieve live metadata from the databases. Contoso identifies the following requirements for
querying data in the FeedbackJson column of the customer-Feedback table:
• Extract the customer feedback text from the JSON document.
• Filter rows where the JSON text contains a keyword.
• Calculate a fuzzy similarity score between the feedback text and a known issue description.
• Orderthe results by similarity score, with the highest score first
View Mode
Q: 8
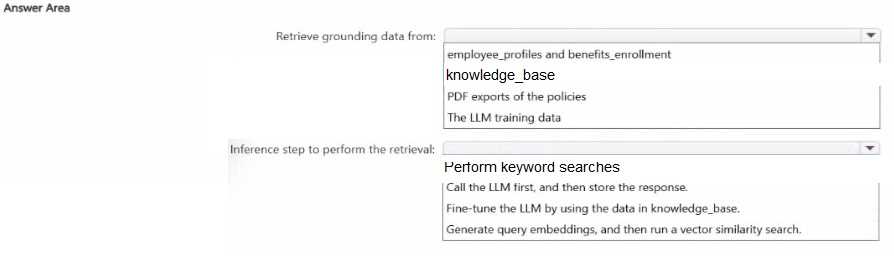
HOTSPOT You have an Azure SQL database that contains a table named knowledgebase, knowledgebase stores human resources (HR) policy documents and contains columns named title, content, category, and embedding. You have an application named App1. App1 queries two relational tables named employee_pnofiles and benefits_enrollnent that contain HR data. App1 hosts a chatbot that calls a large language model (LLM) directly. Users report that the chatbot answers general HR questions correctly but provides outdated or incorrect answers when policies change. The chatbot also fails to answer questions that reference internal policy documents by title or category. You need to recommend a Retrieval Augmented Generation (RAG) solution to resolve the chatbot issues. What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Your Answer
Discussion
No comments yet. Be the first to comment.
Be respectful. No spam.
Correct Answer:
RETRIEVE GROUNDING DATA FROM:KNOWLEDGEBASE
INFERENCE STEP TO PERFORM THE RETRIEVAL:GENERATE QUERY EMBEDDINGS, AND THEN RUN A VECTOR SIMILARITY SEARCH.
Explanation
The chatbot is currently relying on the LLM's parametric memory (its original training data), which causes it to provide outdated answers and fail on internal, proprietary queries. To implement a Retrieval-Augmented Generation (RAG) architecture, you must provide the LLM with up-to-date, domain-specific context.
Since the internal HR policy documents are stored in the knowledgebase table, this must be the source of your grounding data. Additionally, the scenario explicitly notes that the knowledgebase table includes an embedding column. The standard RAG retrieval mechanism utilizes these embeddings by taking the user's input, generating a query embedding at runtime, and performing a vector similarity search against the database's embedding column to find the most semantically relevant policy documents.
References
Microsoft Learn. "Retrieval-Augmented Generation (RAG) in Azure AI Search." Azure Architecture Center. This documentation outlines the standard RAG pattern, confirming that grounding data must be retrieved from a specific knowledge store prior to LLM generation.
Microsoft Learn. "Vector search in Azure SQL Database." Azure SQL Documentation. This details how Azure SQL supports storing vectors (embeddings) and querying them using vector similarity search to feed external AI applications and LLMs.