Contoso has an Azure subscription in North Europe that contains the corporate infrastructure. The current infrastructure contains a Microsoft SQL Server 2017 database. The database contains the following tables.
The FeedbackJson column has a full-text index and stores JSON documents in the following format.
The support staff at Contoso never has the unmask permission.
Requirements
Contoso is deploying a new Azure SQL database that will become the authoritative data store for the following;
• Alworkloads
• Vector search
• Modernized API access
• Retrieval Augmented Generation (RAG) pipelines
Sometimesthe ingestion pipeline fails due to malformed JSON and duplicate payloads.
The engineers at Contoso report that the following dashboard query runs slowly.
SELECT VehicleTd, Lastupdatedutc, EngineStatus, BatteryHealth FROM dbo.VehicleHealthSumary where fleetld- gFleetld ORDER BV LastUpdatedUtc DESC;
You review the execution plan and discover that the plan shows a clustered index scan.
vehicleincidentReports often contains details about the weather, traffic conditions, and location. Analysts report that it is difficult to find similar incidents based on these details
Planned Changes
Contoso wants to modernize Fleet Intelligence Platform to support Al-powered semantic search over
incident reports.
Security Requirements
Contoso identifies the following telemetry requirements:
• Telemetry data must be stored in a partitioned table.
• Telemetry data must provide predictable performance for ingestion and retention operations.
• latitude, longitude, and accuracy JSON properties must be filtered by using an index seek.
Contoso identifies the following maintenance data requirements:
• Ensure that any changes to a row in the MaintenanceEvents table updates the corresponding
value in the LastModif reduce column to the time of the change.
• Avoidrecursive updates.
AI Search, Embedding’s, and Vector indexing
The development learn at Contoso will use Microsoft Visual Studio Code and GitHub Copilot and will
retrieve live metadata from the databases. Contoso identifies the following requirements for
querying data in the FeedbackJson column of the customer-Feedback table:
• Extract the customer feedback text from the JSON document.
• Filter rows where the JSON text contains a keyword.
• Calculate a fuzzy similarity score between the feedback text and a known issue description.
• Orderthe results by similarity score, with the highest score first
View Mode
Q: 10
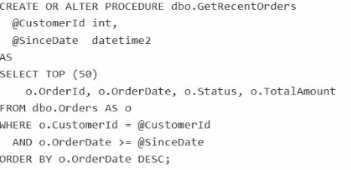
HOTSPOT You have an Azure SQL database that has Query Store enabled Query Performance Insight shows that one stored procedure has the longest runtime. The procedure runs the following parameterized query. The dbo.orders table has approximately 120 million rows. Customer-id is highly selective, and orderOate is used for range filtering and sorting. Vou have the following indexes: • Clustered index: PK_Orders on (Orderld) • Nonclustered index: lx_0rders_order-Date on (OrderDate) with no included columns An actual execution plan captured from Query Store for slow runs shows the following: • An index seek on ixordersorderDate followed by a Key Lookup (Clustered) on PKOrders for customerid, status, and TotalAnount • A sort operator before top (50), because the results are ordered by orderDate DESC For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Your Answer
Discussion
No comments yet. Be the first to comment.
Be respectful. No spam.
Correct Answer:
YES
NO
YES
Explanation
Statement 1 (Yes): The most efficient index for this parameterized query follows the best practice of ordering index keys by Equality, then Inequality/Sort, and finally adding remaining columns to the INCLUDE clause. Making CustomerId (the equality predicate) the leading column allows the database engine to seek directly to the relevant customer. Making OrderDate DESC the secondary key pre-sorts the data exactly as requested by the ORDER BY clause, eliminating the explicit Sort operator. Including Status and TotalAmount makes it a "covering index," which entirely eliminates the expensive Key Lookup operations on the clustered index.
Statement 2 (No): Adding CustomerId as an included column to the existing IX_Orders_OrderDate index does not alter the physical sorting of the index tree, which remains sorted purely by OrderDate. Because CustomerId is an equality filter and highly selective, scanning an index ordered by date to find a specific customer's top 50 recent orders is highly inefficient and will not result in an optimal ordered seek that eliminates the sort. The leading key must be CustomerId to effectively seek and naturally order the results for that specific entity.
Statement 3 (Yes): The captured actual execution plan explicitly reveals structural performance bottlenecks: an unoptimized Index Seek, an expensive Key Lookup, and a Sort operator. These operators represent a high I/O and CPU cost directly attributable to a suboptimal query plan caused by the lack of a properly structured covering index. If the slow runs were primarily due to locking or blocking, the execution plan itself might look optimal, but the wait statistics (e.g., LCK_M_%) would reflect the delay, rather than exposing expensive data retrieval operators.
References
Microsoft Learn: SQL Server Index Architecture and Design Guide
Section: Index Design Basics -> Column Order Considerations.
Details: Confirms that columns used in equality expressions (=) should be listed first in the index key, followed by columns used in inequality or ORDER BY expressions, to avoid sort operations and optimize seeks.
Microsoft Learn: Resolve query performance issues with Query Store
Section: Find queries with suboptimal execution plans.
Details: Explains how Query Store identifies queries with high execution costs due to plan choices (like Key Lookups and explicit Sorts on large tables) versus those suffering from resource waits (like blocking).
Details: Documents that the presence of a Key Lookup indicates an index is not covering and that performance can often be improved by adding a covering index.


 The dbo.orders table has approximately 120 million rows. Customer-id is highly selective, and orderOate is used for range filtering and sorting. Vou have the following indexes: • Clustered index: PK_Orders on (Orderld) • Nonclustered index: lx_0rders_order-Date on (OrderDate) with no included columns An actual execution plan captured from Query Store for slow runs shows the following: • An index seek on ixordersorderDate followed by a Key Lookup (Clustered) on PKOrders for customerid, status, and TotalAnount • A sort operator before top (50), because the results are ordered by orderDate DESC For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
The dbo.orders table has approximately 120 million rows. Customer-id is highly selective, and orderOate is used for range filtering and sorting. Vou have the following indexes: • Clustered index: PK_Orders on (Orderld) • Nonclustered index: lx_0rders_order-Date on (OrderDate) with no included columns An actual execution plan captured from Query Store for slow runs shows the following: • An index seek on ixordersorderDate followed by a Key Lookup (Clustered) on PKOrders for customerid, status, and TotalAnount • A sort operator before top (50), because the results are ordered by orderDate DESC For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. 
