Case Study -
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study -
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview -
Litware, Inc. is a publishing company that has an online bookstore and several retail bookstores worldwide. Litware also manages an online advertising business for the authors it represents.
Existing Environment. Fabric Environment
Litware has a Fabric workspace named Workspace1. High concurrency is enabled for Workspace1.
The company has a data engineering team that uses Python for data processing.
Existing Environment. Data Processing
The retail bookstores send sales data at the end of each business day, while the online bookstore constantly provides logs and sales data to a central enterprise resource planning (ERP) system.
Litware implements a medallion architecture by using the following three layers: bronze, silver, and gold. The sales data is ingested from the ERP system as Parquet files that land in the Files folder in a lakehouse. Notebooks are used to transform the files in a Delta table for the bronze and silver layers. The gold layer is in a warehouse that has V-Order disabled.
Litware has image files of book covers in Azure Blob Storage. The files are loaded into the Files folder.
Existing Environment. Sales Data
Month-end sales data is processed on the first calendar day of each month. Data that is older than one month never changes.
In the source system, the sales data refreshes every six hours starting at midnight each day.
The sales data is captured in a Dataflow Gen1 dataflow. When the dataflow runs, new and historical data is captured. The dataflow captures the following fields of the source:
Sales Date -
Author -
Price -
Units -
SKU -
A table named AuthorSales stores the sales data that relates to each author. The table contains a column named AuthorEmail. Authors authenticate to a guest Fabric tenant by using their email address.
Existing Environment. Security Groups
Litware has the following security groups:
Sales -
Fabric Admins -
Streaming Admins -
Existing Environment. Performance Issues
Business users perform ad-hoc queries against the warehouse. The business users indicate that reports against the warehouse sometimes run for two hours and fail to load as expected. Upon further investigation, the data engineering team receives the following error message when the reports fail to load: “The SQL query failed while running.”
The data engineering team wants to debug the issue and find queries that cause more than one failure.
When the authors have new book releases, there is often an increase in sales activity. This increase slows the data ingestion process.
The company’s sales team reports that during the last month, the sales data has NOT been up-to-date when they arrive at work in the morning.
Requirements. Planned Changes -
Litware recently signed a contract to receive book reviews. The provider of the reviews exposes the data in Amazon Simple Storage Service (Amazon S3) buckets.
Litware plans to manage Search Engine Optimization (SEO) for the authors. The SEO data will be streamed from a REST API.
Requirements. Version Control -
Litware plans to implement a version control solution in Fabric that will use GitHub integration and follow the principle of least privilege.
Requirements. Governance Requirements
To control data platform costs, the data platform must use only Fabric services and items. Additional Azure resources must NOT be provisioned.
Requirements. Data Requirements -
Litware identifies the following data requirements:
Process the SEO data in near-real-time (NRT).
Make the book reviews available in the lakehouse without making a copy of the data.
When a new book cover image arrives in the Files folder, process the image as soon as possible.

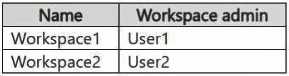 You have a security group named Group1 that contains User1 and User3. The Fabric admin creates the domains shown in the following table.
You have a security group named Group1 that contains User1 and User3. The Fabric admin creates the domains shown in the following table.  User1 creates a new workspace named Workspace3. You add Group1 to the default domain of Domain1. For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
User1 creates a new workspace named Workspace3. You add Group1 to the default domain of Domain1. For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. 

 For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. 
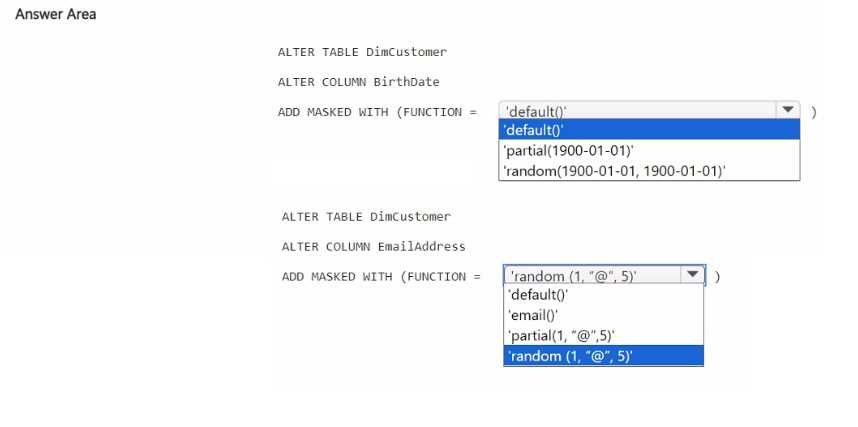
 You need to ensure that the team can view only the first two characters and the last four characters of the Creditcard attribute. How should you complete the statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
You need to ensure that the team can view only the first two characters and the last four characters of the Creditcard attribute. How should you complete the statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 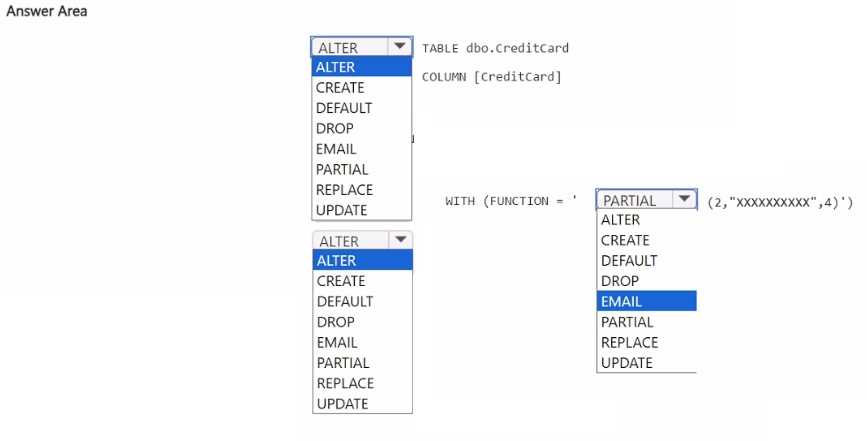
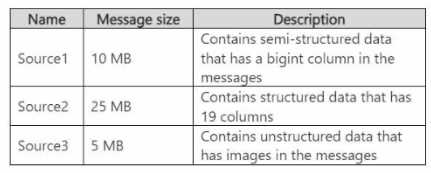 The solution must minimize development effort. What should you include in the recommendation for each source? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
The solution must minimize development effort. What should you include in the recommendation for each source? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 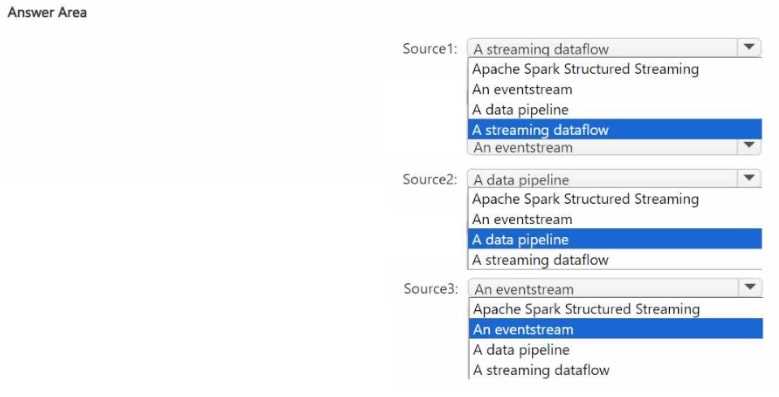
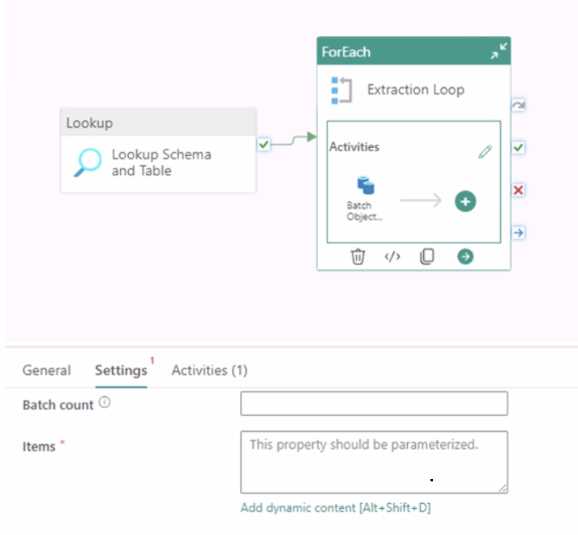 Dynamic Data Copy does NOT use parametrization. You need to configure the ForEach activity to receive the list of tables to be copied. How should you complete the pipeline expression? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
Dynamic Data Copy does NOT use parametrization. You need to configure the ForEach activity to receive the list of tables to be copied. How should you complete the pipeline expression? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. 

 You need to set the Customerkey column as a primary key of the DimCustomer table. Which three code segments should you run in sequence? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
You need to set the Customerkey column as a primary key of the DimCustomer table. Which three code segments should you run in sequence? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order. 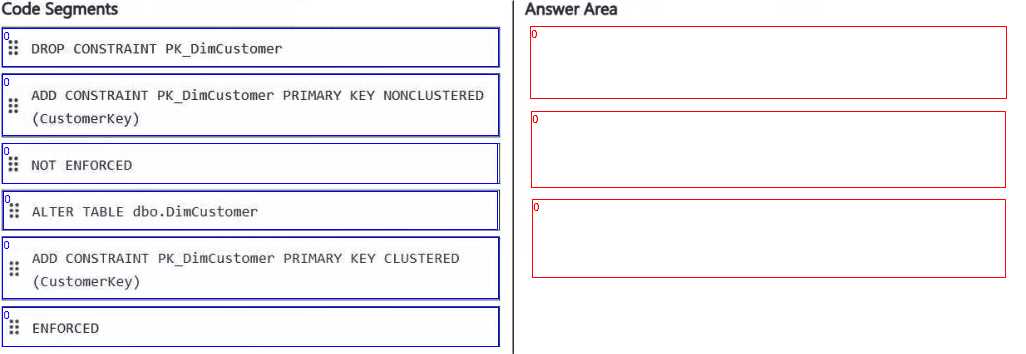
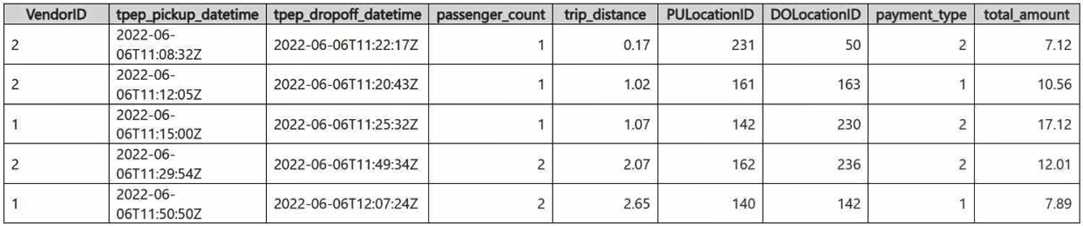 You need to build two KQL queries. The solution must meet the following requirements: One of the queries must partition RunningTotalAmount by VendorID. The other query must create a column named FirstPickupDateTime that shows the first value of each hour from tpep_pickup_datetime partitioned by payment_type. How should you complete each query? To answer, drag the appropriate values the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
You need to build two KQL queries. The solution must meet the following requirements: One of the queries must partition RunningTotalAmount by VendorID. The other query must create a column named FirstPickupDateTime that shows the first value of each hour from tpep_pickup_datetime partitioned by payment_type. How should you complete each query? To answer, drag the appropriate values the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. 
