
HOTSPOT You are evaluating a Python NumPy array that contains six data points defined as follows: data = [10, 20, 30, 40, 50, 60] You must generate the following output by using the k-fold algorithm implantation in the Python Scikit-learn machine learning library: train: [10 40 50 60], test: [20 30] train: [20 30 40 60], test: [10 50] train: [10 20 30 50], test: [40 60] You need to implement a cross-validation to generate the output. How should you complete the code segment? To answer, select the appropriate code segment in the dialog box in the answer area. NOTE: Each correct selection is worth one point. 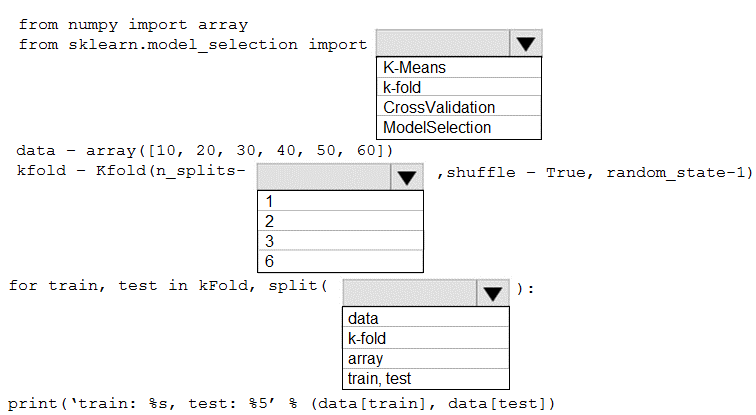
I get why people are picking 2 for n_splits since each test set has 2 samples, but what really matters is the number of folds (so, how many unique train/test pairs). The output shows three pairs, so it lines up with KFold, 3, data. Pretty sure that's what sklearn expects here-correct me if you see it differently!
KFold, 3, data
That matches the splits shown in the question output. Pretty sure since KFold with n_splits=3 gives three folds, and you want to pass your actual data array. Got this type of setup when practicing using the official docs and MS Learn labs-worth reviewing both if this part feels tricky.
I think it’s supposed to be KFold, 3, data for this one. There are three unique train/test splits shown, not just two. The n_splits=2 guess is a common trap here since each test set has two items, but the spec wants number of folds. Agree?
I've seen similar output using n_splits=2 on labs (but could be missing a trick here) so double-check against the official docs or practice questions.
Had something like this in a mock, pretty sure it's B. SAS token lets you specify exact permissions for the blob container which matches the privilege level requirement. The other options can't do that as specifically. Agree?
