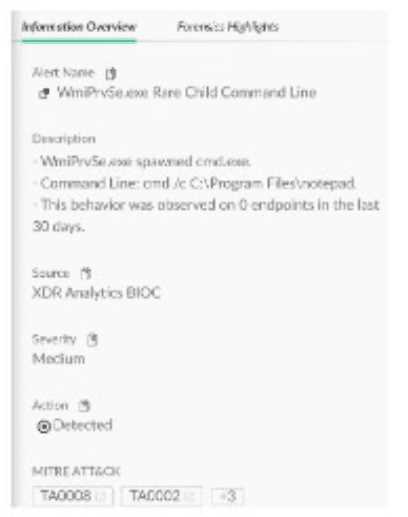
Q: 1
[Cortex XDR Agent Configuration]
Based on the Malware profile image below, what happens when a new custom-developed
application attempts to execute on an endpoint?

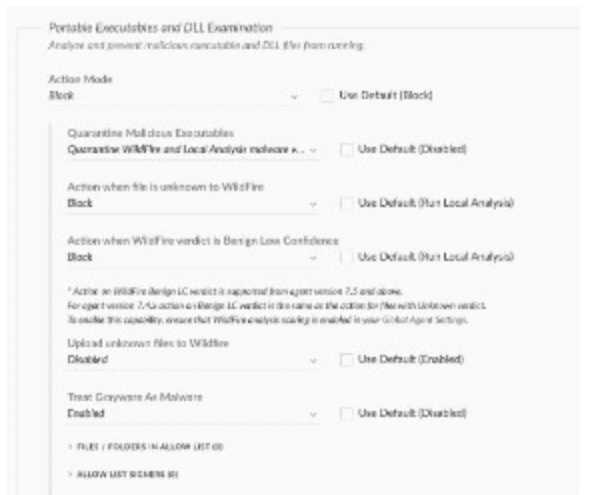
Options
Discussion
Option B. saw a similar question in recent exam reports and the profile blocks unknown apps.
Option B since "block" for unknowns stops custom apps right away. D is tempting but only if there's delay policy.
So tired of these profile image questions where you have to squint. Option B
Probably B, similar question showed up in the official guide and lab walkthroughs.
B
B
Guessing B, but if the profile had "alert" instead of block for unknowns then A would be right.
B , had something like this in a mock. Custom or unknown executables get blocked right away if the policy is set to 'block' for unknowns, so it won't execute at all. Not 100% sure if all versions behave exactly the same, but that's how Palo's usual malware profile works. Agree?
B
B, Block enforcement means new apps like that won't get through. Standard for XDR, pretty sure that's what the image shows.
Be respectful. No spam.