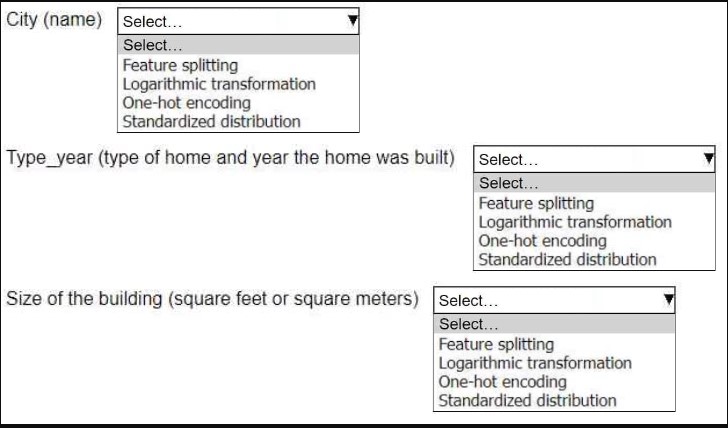
HOTSPOT A company stores historical data in .csv files in Amazon S3. Only some of the rows and columns in the .csv files are populated. The columns are not labeled. An ML engineer needs to prepare and store the data so that the company can use the data to train ML models. Select and order the correct steps from the following list to perform this task. Each step should be selected one time or not at all. (Select and order three.) • Create an Amazon SageMaker batch transform job for data cleaning and feature engineering. • Store the resulting data back in Amazon S3. • Use Amazon Athena to infer the schemas and available columns. • Use AWS Glue crawlers to infer the schemas and available columns. • Use AWS Glue DataBrew for data cleaning and feature engineering. 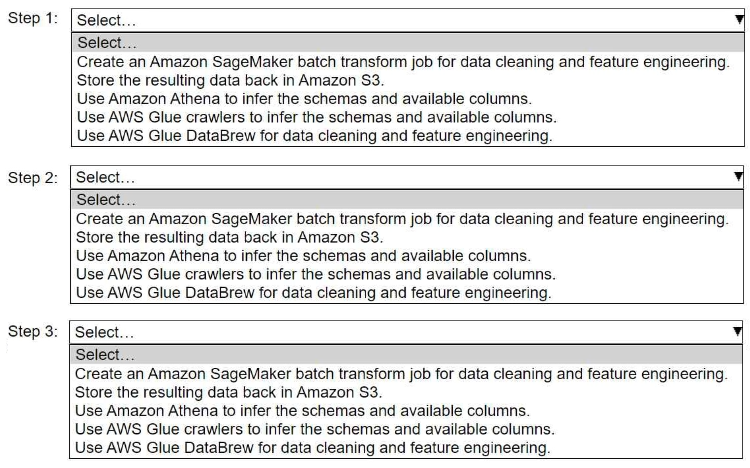
Not quite, it's not Athena first. You need to use Glue crawlers up front to actually infer schema since the files lack headers and are pretty sparse. Athena is more for querying, so that's a trap here. So I'd say: Glue crawler, then DataBrew for cleaning/features, finally save back to S3. Do folks agree?
Looks good to me, pretty consistent with practice and exam reports I’ve seen. Glue crawlers to infer schema first, DataBrew for transformation, save back to S3. I’d check the official AWS docs or do a hands-on lab if you want extra clarity.