
HOTSPOT You are performing exploratory analysis of bus fare data in an Azure Data Lake Storage Gen2 account by using an Azure Synapse Analytics serverless SQL pool. You execute the Transact-SQL query shown in the following exhibit. 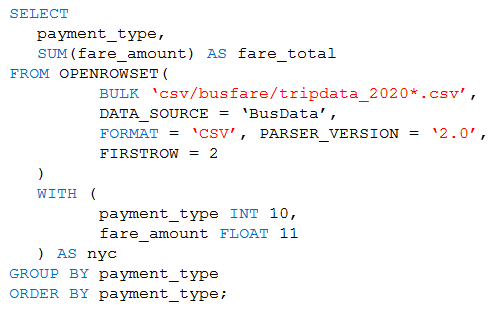 Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. 
Only files starting with tripdata_2020 get processed, not all CSVs. Easy trap since the wildcard is after the prefix, not before. For FIRSTROW = 2, it means the first line is treated as headers. Pretty sure that’s correct, but happy to see counterpoints.
CSV files matching tripdata_2020*.csv get picked up, so only those starting with that prefix in csv/busfare are included. With FIRSTROW = 2, Synapse skips the first row as a header. Pretty sure that's how this T-SQL BULK pattern works. Let me know if someone saw otherwise on practice exams.
