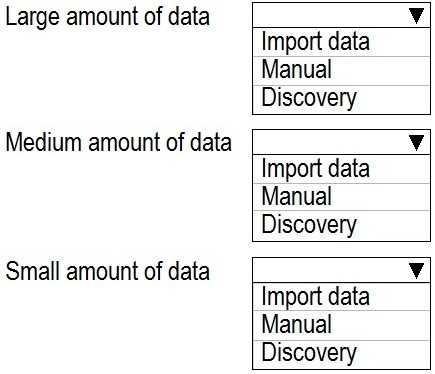
Manual (Large data): Microsoft Learn. "Guidance for designing distributed tables in Azure Synapse Analytics." This documentation details the importance of manually selecting table distribution methods (e.g., hash, round-robin) and column data types, which are fundamental Manual design decisions required for optimizing large-scale data warehouses.
Manual (Large data): Microsoft Learn. "Data types for tables in Azure Synapse Analytics." This guide emphasizes that "Minimizing row size by using the smallest data type that works" is a key principle for improving query performance. This optimization is only possible through a Manual DDL approach, not automated inference.
Import data (Small data): Microsoft Learn. "Get data from a file into a KQL database." This document describes the wizard-based "Get Data" experience in Microsoft Fabric, which "guides you through the process... [including] creating a new table, mapping the data, and ingesting the data." This automated flow is the definition of the Import data method, perfect for small, simple ingestion tasks.
Discovery (Medium data): Microsoft Learn. "Schema drift in mapping data flow." (Azure Data Factory documentation). This document discusses the feature of "schema discovery," which allows a developer to "discover the schema of your data source on the fly" and "see the changing columns." This concept of inspecting and adapting to a schema, rather than just blindly importing or fully manually creating it, aligns with the Discovery approach for medium-sized or evolving datasets.