
Q: 7
You are building a pipeline to process time-series dat
a. Which Google Cloud Platform services should you put in boxes 1,2,3, and 4?

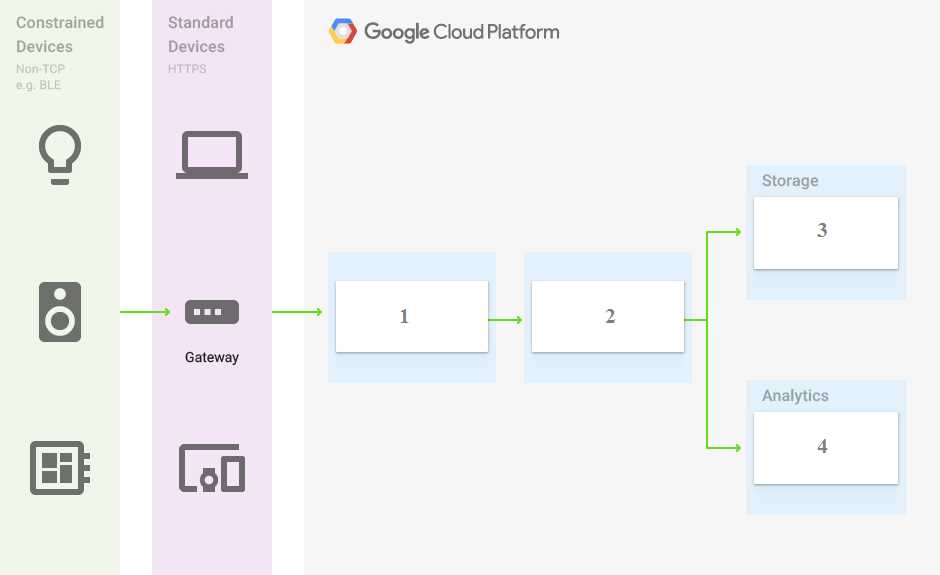
Options
Discussion
D. Saw a similar question in recent exam reports, matches the best for real-time time-series processing using GCP services.
I don’t think it’s D. C looks better since Cloud Storage comes right after Pub/Sub, which would handle raw event storage before anything else happens. That makes sense if you want to keep all incoming data, even before processing. Not totally sure but that’s how I’d see it.
D seems most likely for streaming, but still not fully sure since it depends if raw storage is needed first. Anyone pick C and pass with that?
Probably D here. Pub/Sub handles the stream, Dataflow processes it, then Bigtable is great for fast time-series inserts, with BigQuery for analytics. Only thing is if raw storage was required I'd look at C, but doesn't seem like it.
D
C/D? Based on the official guide and hands-on labs, D matches best for a streaming time-series pipeline-Dataflow and Bigtable are built for real-time data. But sometimes exam questions want Cloud Storage for retention, so can't be 100% sure. Anyone else double-check in practice tests?
C/D? I've seen both come up for questions like this. D is better for real-time streaming pipelines but sometimes they throw in a twist about persistent storage (which would mean C). Not certain which one they're looking for in this context.
Did anyone check against the official guide and labs? Practice test looks like it covers similar pipelines.
Is there a requirement to store the raw time-series data long term before processing? If not, Cloud Dataflow and Bigtable (D) make sense since they fit real-time streaming best. Just wondering if anyone saw the question specify permanent storage upfront.
D imo
Be respectful. No spam.
