Q: 1
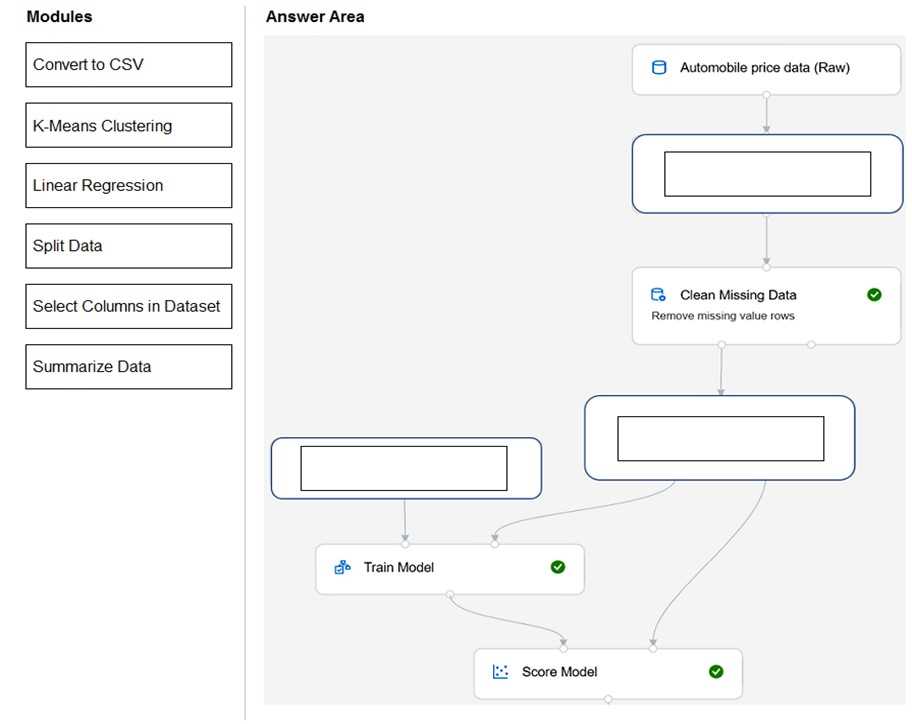
You need to create a training dataset and validation dataset from an existing dataset.
Which module in the Azure Machine Learning designer should you use?
Options
Discussion
C. not B. Add Rows just merges datasets so that's a trap. Split Data does what the question asks, pretty sure.
This question always bugs me, Azure's UI never makes it obvious. Pretty sure it's C since Split Data literally does what they're asking for, but if they'd said you need to build a dataset from pieces I'd hesitate. Anyone think B could be right in some edge case?
C just the Split Data module. No need to overthink it.
C is the way to go. The Split Data module in Azure ML designer is made for this exact job, splitting out training and validation sets from a single dataset. Saw similar logic on some Microsoft practice tests and in the docs. If anyone isn't sure, official learning paths cover this.
Option C Can't think of a case where you'd need anything but Split Data for this.
I don’t think it’s B. C is built for splitting a dataset into training and validation, which is exactly what’s needed here. B (Add Rows) is more for combining data, not splitting. Seen this kind of trap before.
Its C, had something like this in a mock and Split Data was the move.
C
C not B. Add Rows is tempting but it's joining, not splitting. Split Data is what you need for training/validation sets, seen that on similar questions.
B tbh. Since creating a new dataset could mean putting rows together, I thought Add Rows fits. Might be misreading what "create" means here, but didn't see Split Data as the obvious move at first. Open to being corrected.
Be respectful. No spam.