
Q: 1
A company’s web server availability was breached by a DDoS attack and was offline for 3 hours
because it was not deemed a critical asset in the incident response playbook. Leadership has
requested a risk assessment of the asset. An analyst conducted the risk assessment using the threat
sources, events, and vulnerabilities. Which additional element is needed to calculate the risk?
Options
Discussion
Option D. The risk model framework's needed to actually do the calculation. Methodology matters for leadership, so D fits better than B.
D , though I kinda see why some might pick B. Risk model framework gives you the actual structure for calculation here.
D imo, saw exactly similar question in my exam. D is the only one that lets you actually structure the risk calculation.
Nah, not B here-D is the missing piece. Event severity/likelihood is tempting but you need a framework to quantify risk.
Probably B here, since knowing how severe and likely an event is seems key for calculating risk. Asset value and threats are important but without severity/likelihood it’s hard to quantify. I think I’ve seen similar questions in other practice sets.
Be respectful. No spam.
 An engineer received multiple reports from employees unable to log into systems with the error: The
Group Policy Client service failed to logon – Access is denied. Through further analysis, the engineer
discovered several unexpected modifications to system settings. Which type of breach is occurring?
An engineer received multiple reports from employees unable to log into systems with the error: The
Group Policy Client service failed to logon – Access is denied. Through further analysis, the engineer
discovered several unexpected modifications to system settings. Which type of breach is occurring?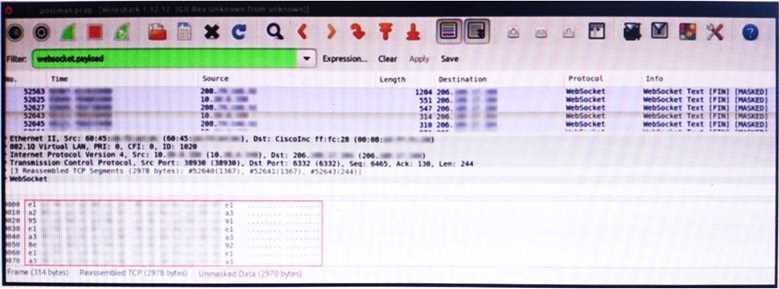 An engineer is analyzing this Vlan0386-int12-117.pcap file in Wireshark after detecting a suspicious
network activity. The origin header for the direct IP connections in the packets was initiated by a
google chrome extension on a WebSocket protocol. The engineer checked message payloads to
determine what information was being sent off-site but the payloads are obfuscated and unreadable.
What does this STIX indicate?
An engineer is analyzing this Vlan0386-int12-117.pcap file in Wireshark after detecting a suspicious
network activity. The origin header for the direct IP connections in the packets was initiated by a
google chrome extension on a WebSocket protocol. The engineer checked message payloads to
determine what information was being sent off-site but the payloads are obfuscated and unreadable.
What does this STIX indicate?